1. 物联网时序大数据补全技术
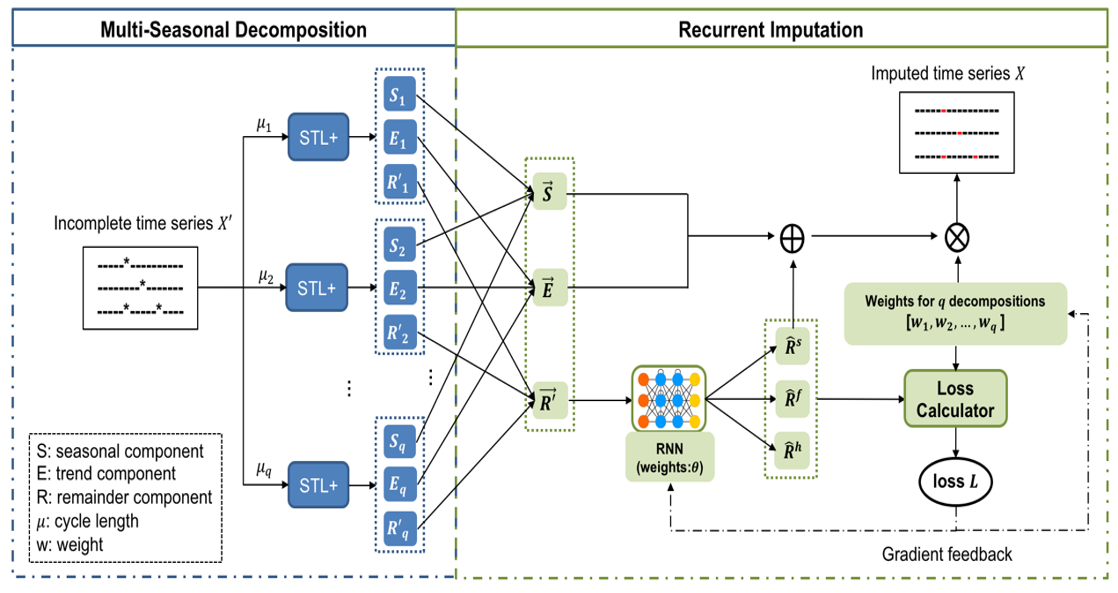
创新研究了物联网时序数据补全技术,将统计模型与深度学习模型有效结合,有效解决了物联网传感器数据缺失问题。
2. 基于自然语言处理的非结构化文本脱敏关键技术
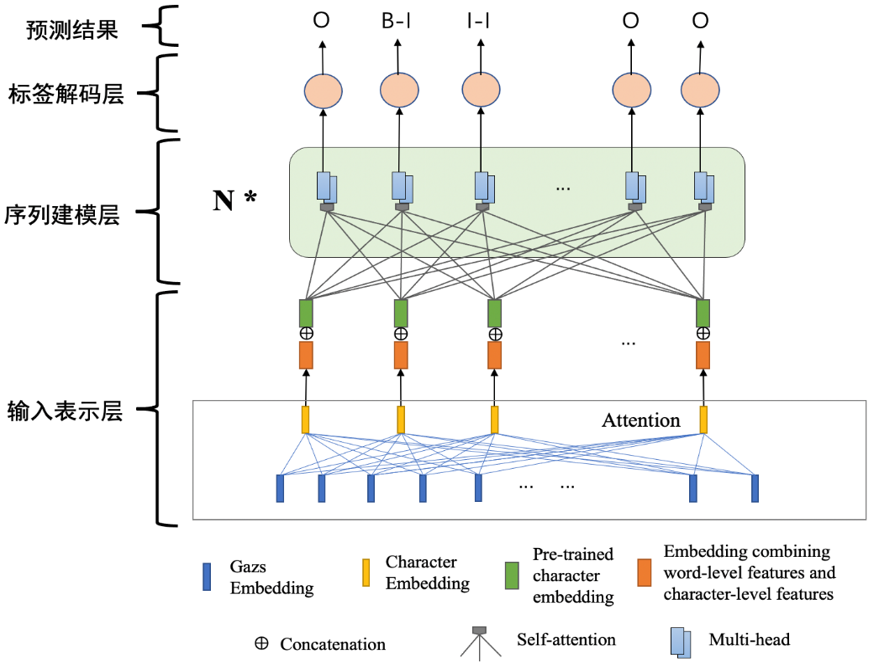
基于自然语言处理的非结构化文本脱敏关键技术,创新提出了BERT-Attention-LSTM-CRF算法,敏感信息识别准确率高达98%,有效解决敏感数据的安全共享问题。
3. 企业“五维”安全画像模型
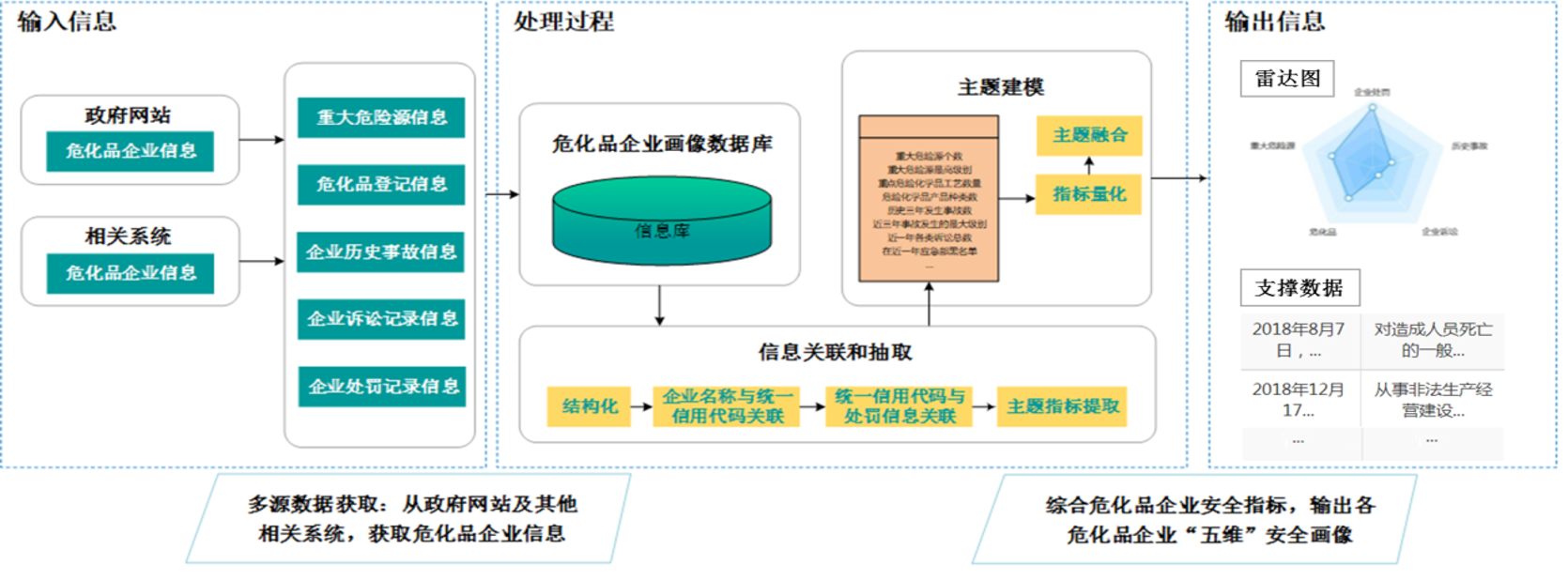
针对危化品企业,创新地提出了“五维安全画像模型”。针对企业监管数据来源复杂多变、容易造假等问题,将层次分析、信息关联、用户画像等方法与企业安全风险评估场景深度融合。从互联网数据中选取了12个客观反映企业安全的数据指标构建评估模型,缓解了企业风险评估主观性高、公平性弱的问题,改变了企业评估需要专家、依赖人工打分的传统方式。
4. 洪涝情景下的应急救援路径规划和应急救援力量调度模型
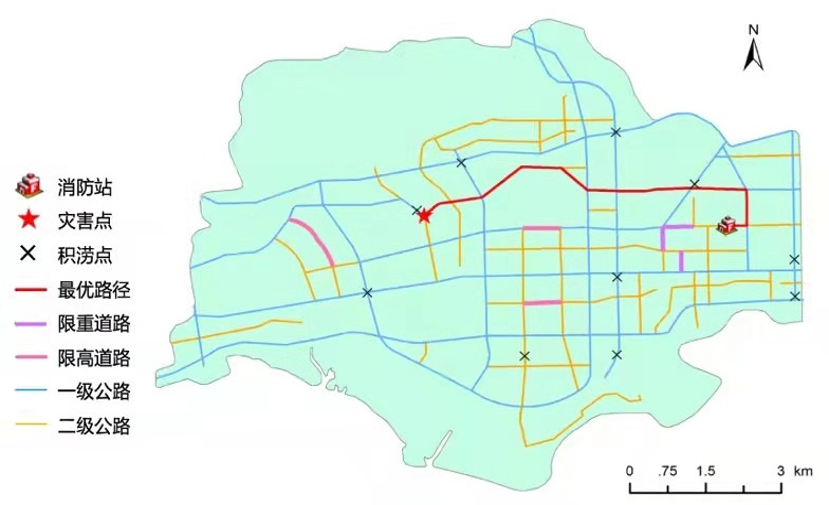
在应急调度方面,提出了洪涝情景下的应急救援路径规划和应急救援力量调度模型。该模型针对城市内涝场景,根据内涝程度为救援车辆规划最优救援路径,并根据受灾点的积涝风险对救援力量进行动态调度。考虑受灾影响下的最短时间路径,提出创新的customized A*算法,保证路径最优的前提下,提高求解速率,为应急救援赢得时间。该方法综合考虑救援路径上的车流量影响,并大幅提高了算法运行效率,更适用于需要快速决策的应急指挥场景。
5. 跨语言迁移场景下微调多语言预训练编码器的新型方法
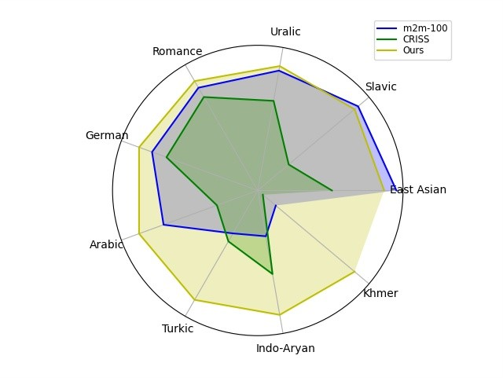
在训练多语言机器翻译系统时,传统方法要求使用多种语言的标注数据。由于数据不足,低资源语言的翻译效果差。我们提出基于多语言预训练模型的跨语言迁移方法,使用六种辅助语言的标注数据,模型训练后可以翻译100种源语言语句,且翻译准确率较同类型公开模型(Facebook公司的CRISS和m2m-100)高21%-31%。该方法将在微软公司的翻译产品中应用。
6. 基于新型词对齐模型的受控机器翻译解码算法
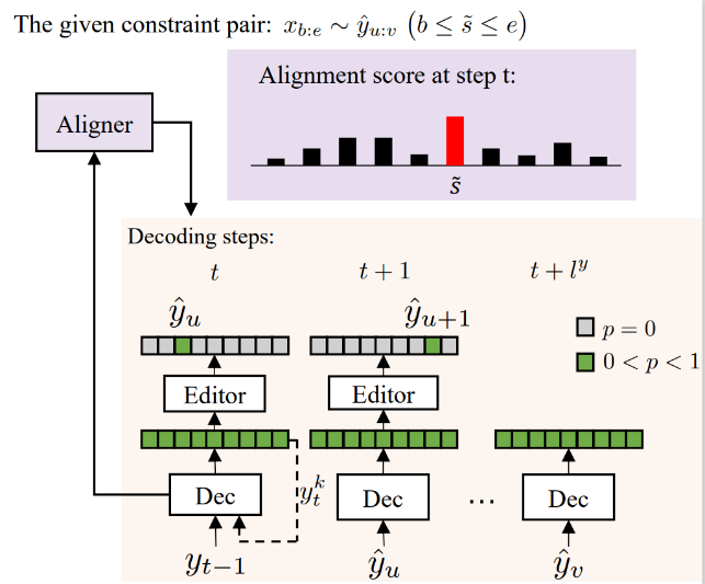
在短语约束的受限机器翻译任务中,已有方法采用传统词对齐模型进行受限翻译。然而传统词对齐模型计算速度慢或效果欠佳,导致受限翻译的效果不佳。我们提出基于新型词对齐模型的受控机器翻译解码算法,基于更加准确的词对齐模型实现快速受限翻译。翻译准确率较基准模型提升4%,约束成功率较基准模型提升11%。
7. 基于多语言预训练模型的非自回归机器翻译模型
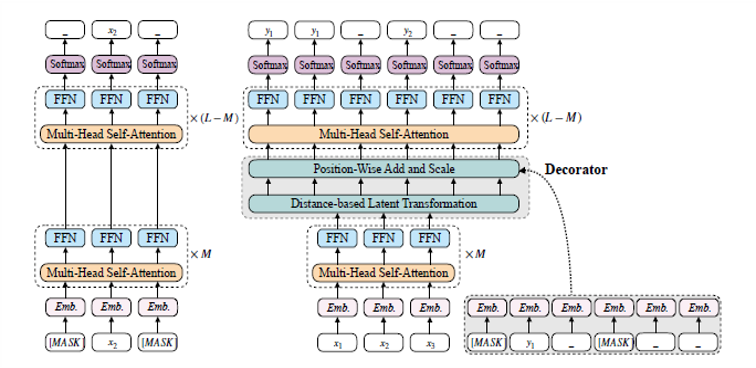
在训练非自回归机器翻译模型时,传统非自回归方法没有引入预训练模型,无法有效利用大规模单语语料。我们提出基于多语言预训练模型的非自回归机器翻译模型,利用预训练中的掩码预测任务辅助非自回归生成任务,在不降低翻译质量的情况下,解码速度提升至标准Transformer模型的19.9倍。
8. 基于对比学习和知识蒸馏的多语言图文检索模型
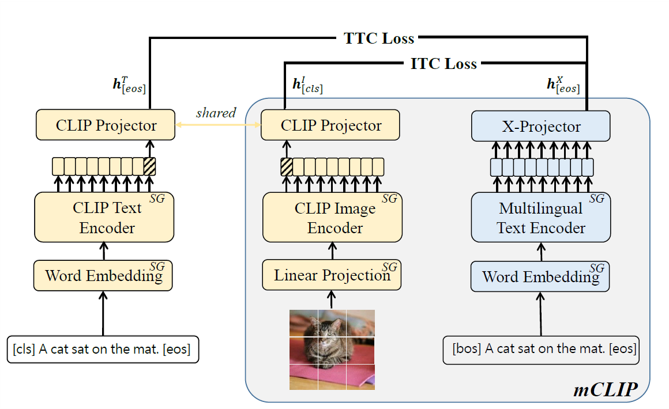
在训练多语言图文预训练模型时,传统方法要求使用不同语言的图文标注数据和大规模的平行文本语料,模型训练过程复杂。我们提出基于对比学习和知识蒸馏的多语言图文检索模型,仅采用英文的图文标注数据实现英文图文预训练模型和多语言文本预训练模型的对齐,以24%的平行文本语料和更低的计算成本在检索性能上媲美Google公司的MURAL模型。该方法将在华为公司的图文检索系统中应用。
9. 计算成像重构
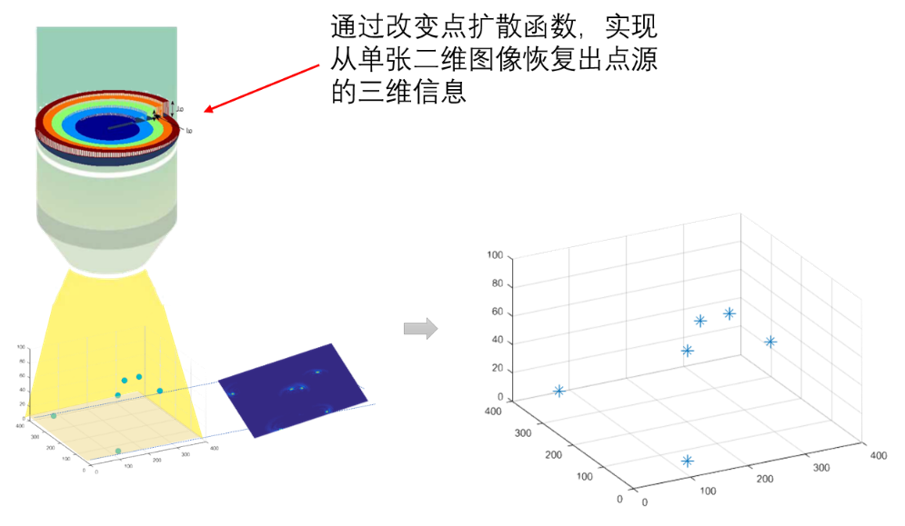
通过单张二维观测图像,获取三维点源的高分辨率定位与成像。本研究不仅对基于点扩散函数的三维定位问题带来数学模型与算法,且对数学与交叉学科领域(特别是稀疏恢复的反问题领域)带来新的应用。
10. 生物医学成像分析
通过半监督学习,充分利用无标签数据;通过主动式学习,高效地识别出较为需标签数据。结合两项技术,做到仅利用少量标签数据,即可做到图像分割。所求得的模型与全监督式学习的结果相媲美,并超越当前最先进的半监督式学习10% 的IoU分数和DICE系数。
11. 数据统计建模、行为决策与可视化
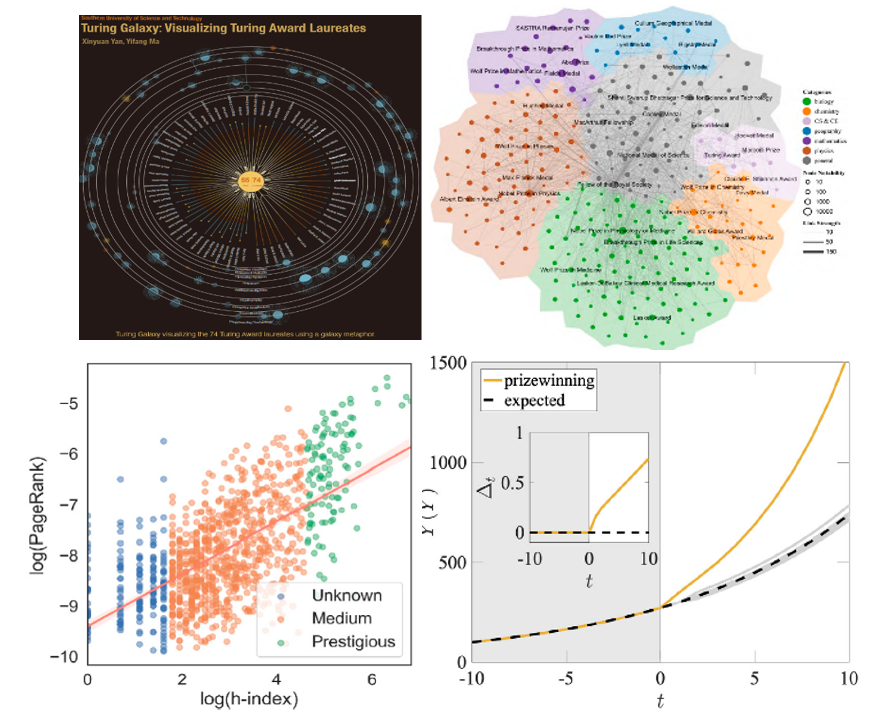
通过对大规模数据进行统计建模,揭示系统背后的运行规律从而产生社会、商业价值。对大规模观测数据进行量化分析,对其中的经济、社会现象进行解释与预测,助力行为决策。以交互图形的形式展示数据中的线性、非线性结构,达到对数据的动态展示、需求定制、人机交互以及可视化分析。
1. 华为火花奖

2. 中国航空学会科学进步二等奖

3. 中国仪器仪表学会科学进步三等奖
